double array trie,字典树(trie)结构的一种高效实现方式,与传统字典树相比,压缩存储更省空间,精巧的状态机设计访问更快速,数组线性存取对缓存也更友好,不足之处主要在于构造(插入)过程中冲突解决稍复杂、缓慢。
double array trie的提出及构造算法源于日本人Aoe的论文,实质上是个确定有限状态自动机,所谓双数组则分别对应base数组和check数组:
base[s] :状态(节点)数组,存储s节点状态转移的基地址。
check[t] :存储对应t节点的父节点索引,用于构造(插入)过程中的冲突检查。
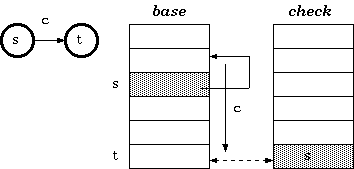
以上图为例,从s状态节点转移到t节点,c为状态转移的跳转偏移步长,实质是以边的形式存储字符串的单个字符,上图构造过程中始终遵循以下规则:
base[s] + c = t
check[t] == s
访问过程自然非常简单明了,这个数据结构的实现难点主要在于构造过程中的冲突,例如从已有s1节点指向t节点,插入时s2节点也将指向t节点,而t节点不应该同时存在两个父节点,这时就需要移动调整,冲突严重时节点的调整范围和频次将会相当大。
构造过程如何减少冲突?自然也能解决插入缓慢的问题,大部分的工程应用场景下,我们主要用于存储一些静态词典,也就是说双数组树更适合应用于离线的静态词典构建,相关论文也提出了对于静态词典事先排序好再进行构建,将会大大减少冲突,也能做到更好的空间压缩,提高检索速度。
Refer:
1. An Efficient Implementation of Trie Structures
2. An Efficient Language Model Using Double-Array Structures
aa