MemTable的底层实现依赖于两大核心组件Arena和SkipList,Arena内存分配器统一管理内存,SkipList用于实际KV存储。Arena前面已做过详细分析,本文从MemTable的读写具体实现,KV的实际存储格式、跳表的相关接口及具体实现、线程安全等一一道来。
首先要大赞下Google家的C++代码风格和质量在leveldb中的体现,对模板、函数对象(仿函数)、类层次组织、语言上的某些细节特性等的设计和使用相当规范、简洁、清晰、易读,也很注重性能,质量上乘,是学习C++语言的不二之选。
好,回归正题,先来看MemTable的接口:
class MemTable {
public:
// MemTables are reference counted. The initial reference count
// is zero and the caller must call Ref() at least once.
explicit MemTable(const InternalKeyComparator& comparator);
// Increase reference count.
void Ref() { ++refs_; }
// Drop reference count. Delete if no more references exist.
void Unref() {
--refs_;
assert(refs_ >= 0);
if (refs_ <= 0) {
delete this;
}
}
// Returns an estimate of the number of bytes of data in use by this
// data structure. It is safe to call when MemTable is being modified.
size_t ApproximateMemoryUsage();
// Return an iterator that yields the contents of the memtable.
//
// The caller must ensure that the underlying MemTable remains live
// while the returned iterator is live. The keys returned by this
// iterator are internal keys encoded by AppendInternalKey in the
// db/format.{h,cc} module.
Iterator* NewIterator();
// Add an entry into memtable that maps key to value at the
// specified sequence number and with the specified type.
// Typically value will be empty if type==kTypeDeletion.
void Add(SequenceNumber seq, ValueType type,
const Slice& key,
const Slice& value);
// If memtable contains a value for key, store it in *value and return true.
// If memtable contains a deletion for key, store a NotFound() error
// in *status and return true.
// Else, return false.
bool Get(const LookupKey& key, std::string* value, Status* s);
private:
~MemTable(); // Private since only Unref() should be used to delete it
struct KeyComparator {
const InternalKeyComparator comparator;
explicit KeyComparator(const InternalKeyComparator& c) : comparator(c) { }
int operator()(const char* a, const char* b) const;
};
friend class MemTableIterator;
friend class MemTableBackwardIterator;
typedef SkipList<const char*, KeyComparator> Table;
KeyComparator comparator_;
int refs_;
Arena arena_;
Table table_;
// No copying allowed
MemTable(const MemTable&);
void operator=(const MemTable&);
};
MemTable的对象构造必须显式调用(explicit关键字),重点在于初始Arena和SkipList两大核心组件,且提供引用计数初始为0,使用时必须先Ref(),实际对象销毁在Unref()引用计数为0时。当然InternalKeyComparator也需要MemTable对象构造时指定,SkipList按照InternalKey升序排列。
NewIterator()用于创建一个MemTableIterator对象,而MemTableIterator是SkipList的Iterator的wrapper,可用于对MemTable的实际存储数据进行迭代按key有序访问。
需要注意的是,MemTableIterator的key()通过对SkipList的Node反解得到的是internal_key,value()返回的则是实际的数据值。
再看读写接口,Add通过指定SequenceNumber、ValueType、user_key及实际value将封装好的KV块插入跳表中;Get通过指定LookupKey获取value及Status。这里一定要明确区分LookupKey、user_key、memtable_key、internal_key等基本概念的区别,后面会附图示意区分。
下面看Add的详细实现:
void MemTable::Add(SequenceNumber s, ValueType type,
const Slice& key,
const Slice& value) {
size_t key_size = key.size();
size_t val_size = value.size();
size_t internal_key_size = key_size + 8;
const size_t encoded_len =
VarintLength(internal_key_size) + internal_key_size +
VarintLength(val_size) + val_size;
char* buf = arena_.Allocate(encoded_len);
char* p = EncodeVarint32(buf, internal_key_size);
memcpy(p, key.data(), key_size);
p += key_size;
EncodeFixed64(p, (s << 8) | type);
p += 8;
p = EncodeVarint32(p, val_size);
memcpy(p, value.data(), val_size);
assert((p + val_size) - buf == encoded_len);
table_.Insert(buf);
}
上面是构造KV entry的过程,可以看到KV的实际存储格式如下图: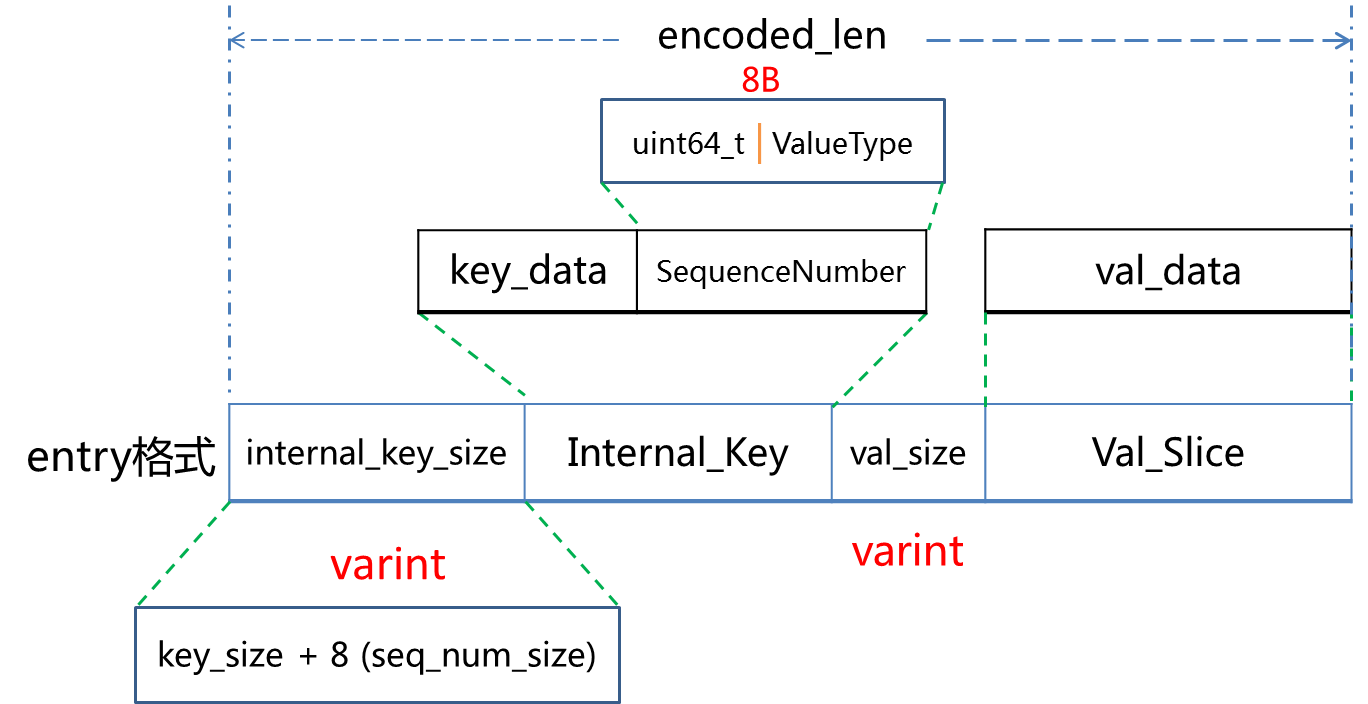
由上述代码可知SequenceNumber只使用了56bit,小端低位8bit为ValueType;亦可以看到Internal_Key和Val_Slice的大小均使用了varint变长压缩,即使用单字节最高位来区分是否还有后续字节,用前7位存储实际比特数据,对于小整数有比较好的压缩效果,这种对小整数的字节对齐压缩方案在leveldb实现中有较多体现。
结合上图,再看下各种key的区别如下: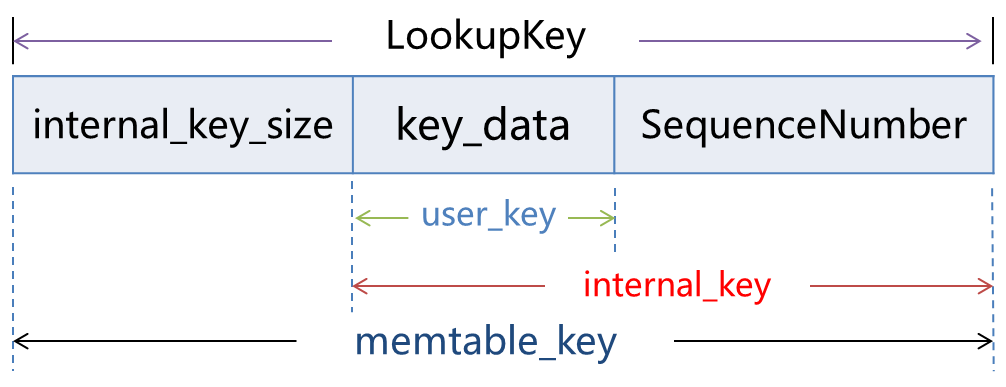
再看Get的具体实现:
bool MemTable::Get(const LookupKey& key, std::string* value, Status* s) {
Slice memkey = key.memtable_key();
Table::Iterator iter(&table_);
iter.Seek(memkey.data());
if (iter.Valid()) {
// Check that it belongs to same user key. We do not check the
// sequence number since the Seek() call above should have skipped
// all entries with overly large sequence numbers.
const char* entry = iter.key();
uint32_t key_length;
const char* key_ptr = GetVarint32Ptr(entry, entry+5, &key_length);
if (comparator_.comparator.user_comparator()->Compare(
Slice(key_ptr, key_length - 8),
key.user_key()) == 0) {
// Correct user key
const uint64_t tag = DecodeFixed64(key_ptr + key_length - 8);
switch (static_cast(tag & 0xff)) {
case kTypeValue: {
Slice v = GetLengthPrefixedSlice(key_ptr + key_length);
value->assign(v.data(), v.size());
return true;
}
case kTypeDeletion:
*s = Status::NotFound(Slice());
return true;
}
}
}
return false;
}
Get通过构造LookupKey(其中ValueType默认指定为kTypeValue)请求,查询时构造SkipList的Iterator来seek指定的节点。需要注意Add时添加的是整个KV entry块,Get时只传入LookupKey,seek跳表节点时实际通过反解出internal_key最终提取user_key进行比较,若user_key相同,再比较SequenceNumber,因SequenceNumber具有唯一性,能保证获取最新版本的数据(可能会有数据删除),具体比较过程可参看InternalKeyComparator::Compare函数;而seek是通过FindGreaterOrEqual来查找节点,当相应节点不为空(迭代器Valid)时需再次校验该节点是否同属同一user_key, 若相同且不删除则返回相应的value。
特别强调下相同user_key在跳表里的排序,以下标作为SequenceNumber,举例如下:
a2, a1, b3, b2, c6, c1,实际是这样排列,能够确保查找时首先获取的是最新版本的数据。
在key的比较过程中涉及大量的字符串比较,leveldb定制了字符串处理的类Slice,看下其实现:
inline int Slice::compare(const Slice& b) const {
const size_t min_len = (size_ < b.size_) ? size_ : b.size_;
int r = memcmp(data_, b.data_, min_len);
if (r == 0) {
if (size_ < b.size_) r = -1;
else if (size_ > b.size_) r = +1;
}
return r;
}
Slice的compare版本相比glibc库函数strcmp实现更高效,作了多点优化,min_len 和更高效的内存memcmp,尤其在MemTable的读写过程中频繁使用的场景收益和效果都很明显。
下面来看下SkipList的实现,也会参考redis中跳表实现并作相应比较。先看SkipList接口如下:
template<typename Key, class Comparator>
class SkipList {
private:
struct Node;
public:
// Create a new SkipList object that will use "cmp" for comparing keys,
// and will allocate memory using "*arena". Objects allocated in the arena
// must remain allocated for the lifetime of the skiplist object.
explicit SkipList(Comparator cmp, Arena* arena);
// Insert key into the list.
// REQUIRES: nothing that compares equal to key is currently in the list.
void Insert(const Key& key);
// Returns true iff an entry that compares equal to key is in the list.
bool Contains(const Key& key) const;
private:
enum { kMaxHeight = 12 };
// Immutable after construction
Comparator const compare_;
Arena* const arena_; // Arena used for allocations of nodes
Node* const head_;
// Modified only by Insert(). Read racily by readers, but stale
// values are ok.
port::AtomicPointer max_height_; // Height of the entire list
inline int GetMaxHeight() const {
return static_cast(
reinterpret_cast(max_height_.NoBarrier_Load()));
}
// Read/written only by Insert().
Random rnd_;
Node* NewNode(const Key& key, int height);
int RandomHeight();
bool Equal(const Key& a, const Key& b) const { return (compare_(a, b) == 0); }
// Return true if key is greater than the data stored in "n"
bool KeyIsAfterNode(const Key& key, Node* n) const;
// Return the earliest node that comes at or after key.
// Return NULL if there is no such node.
//
// If prev is non-NULL, fills prev[level] with pointer to previous
// node at "level" for every level in [0..max_height_-1].
Node* FindGreaterOrEqual(const Key& key, Node** prev) const;
// Return the latest node with a key < key.
// Return head_ if there is no such node.
Node* FindLessThan(const Key& key) const;
// Return the last node in the list.
// Return head_ if list is empty.
Node* FindLast() const;
// No copying allowed
SkipList(const SkipList&);
void operator=(const SkipList&);
};
leveldb往MemTable存储数据采用了跳表这个数据结构,实质是节点含有层次的有序链表,并没有使用如B树、红黑树、平衡二叉树等树形结构,个人认为主要是考虑到实现简单,数据有序,高度随机生成(高度增加概率按照以1/4因子等比递减),亦能达到如树形结构的插入或查找效率。简单而不失高效,何乐而不为,而且在redis的ZSET结构中底层实现亦采用跳表,可见也是一种共识。因跳表在网上有大量资料,不再作图予以表意。
相比redis的跳表实现,主体结构上并无太大差异,节点高度均是随机生成,为了结构体的紧凑且变长、地址连续、节省内存等也都使用了柔性数组成员这个小trick。主要区别在于排序时redis按照双精度浮点score,而leveldb按照internal_key对应comparator;由于redis ZSET的业务需要对节点增加了回溯指针,leveldb没有;redis跳表节点对应每层还有个用于计算节点排名(rank)的跨度span,leveldb也没有。
下面着重说明下柔性数组使用的小trick,为了方便对比将redis的代码片段放一块:
// redis 的跳表节点声明
typedef struct zskiplistNode {
robj *obj;
double score;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;
} level[];
} zskiplistNode;
// leveldb 的跳表节点声明
template<typename Key, class Comparator>
struct SkipList<Key,Comparator>::Node {
explicit Node(const Key& k) : key(k) { }
Key const key;
// Accessors/mutators for links. Wrapped in methods so we can
// add the appropriate barriers as necessary.
Node* Next(int n) {
assert(n >= 0);
// Use an 'acquire load' so that we observe a fully initialized
// version of the returned Node.
return reinterpret_cast<Node*>(next_[n].Acquire_Load());
}
void SetNext(int n, Node* x) {
assert(n >= 0);
// Use a 'release store' so that anybody who reads through this
// pointer observes a fully initialized version of the inserted node.
next_[n].Release_Store(x);
}
// No-barrier variants that can be safely used in a few locations.
Node* NoBarrier_Next(int n) {
assert(n >= 0);
return reinterpret_cast<Node*>(next_[n].NoBarrier_Load());
}
void NoBarrier_SetNext(int n, Node* x) {
assert(n >= 0);
next_[n].NoBarrier_Store(x);
}
private:
// Array of length equal to the node height. next_[0] is lowest level link.
port::AtomicPointer next_[1];
};
redis对于跳表节点层高使用了未指定大小的数组声明,而leveldb默认加入了最低层次的一个节点指针数组,由于C/C++标准规定不能定义长度为0的数组,但这种结构又在某些场景下特别有用,编译器对此做了扩展,前者redis使用的方式也是C99标准,并不占用整体结构体的大小,后者leveldb实现占用了一个节点指针大小,但仍然支持变长连续的结构体扩展。所以这种声明数组大小不指定,指定为0或1均可以,只不过不指定和指定为0是不占用结构体空间的。
下面以跳表节点的插入为例,分析插入过程:
template
void SkipList<Key,Comparator>::Insert(const Key& key) {
// TODO(opt): We can use a barrier-free variant of FindGreaterOrEqual()
// here since Insert() is externally synchronized.
Node* prev[kMaxHeight];
Node* x = FindGreaterOrEqual(key, prev);
// Our data structure does not allow duplicate insertion
assert(x == NULL || !Equal(key, x->key));
int height = RandomHeight();
if (height > GetMaxHeight()) {
for (int i = GetMaxHeight(); i < height; i++) {
prev[i] = head_;
}
//fprintf(stderr, "Change height from %d to %d\n", max_height_, height);
// It is ok to mutate max_height_ without any synchronization
// with concurrent readers. A concurrent reader that observes
// the new value of max_height_ will see either the old value of
// new level pointers from head_ (NULL), or a new value set in
// the loop below. In the former case the reader will
// immediately drop to the next level since NULL sorts after all
// keys. In the latter case the reader will use the new node.
max_height_.NoBarrier_Store(reinterpret_cast<void*>(height));
}
x = NewNode(key, height);
for (int i = 0; i < height; i++) {
// NoBarrier_SetNext() suffices since we will add a barrier when
// we publish a pointer to "x" in prev[i].
x->NoBarrier_SetNext(i, prev[i]->NoBarrier_Next(i));
prev[i]->SetNext(i, x);
}
}
首先通过FindGreaterOrEqual以返回待查数据所在位置的下一个节点(由于唯一SequenceNumber的存在能确保不会插入相同key),同时保存正查找节点的各层前驱于pre数组中,这样也可以为查找复用,然后随机分配层高,如果层高大于当前跳表的最大层高,就要更新相差的那部分层高对应前驱数组为跳表头结点,最后分配新节点,像链表插入那样先修改新节点后继,再修改前驱节点的后继为当前新节点。
这里再强调下分配新节点NewNode:
template<typename Key, class Comparator>
typename SkipList<Key,Comparator>::Node*
SkipList<Key,Comparator>::NewNode(const Key& key, int height) {
char* mem = arena_->AllocateAligned(
sizeof(Node) + sizeof(port::AtomicPointer) * (height - 1));
return new (mem) Node(key);
}
分配新阶段的内存使用了对齐版本的AllocateAligned,而在指定的内存地址上创建对象使用了placement new。
placement new是重载operator new的一个标准、全局的版本,它不能被自定义的版本代替(不像普通的operator new和operator delete能够被替换成用户自定义的版本),允许你在一个已经分配好的内存中(栈或堆中)构造一个新的对象,主要有两点好处:
1)在已分配好的内存上进行对象的构建,构建速度快。
2)已分配好的内存可以反复利用,有效的避免内存碎片问题。
从插入操作,来看下线程安全,注释也有说明,使用有内存屏障修改新节点的前驱,无内存屏障修改新节点的后继,可以看出多线程多写时需要业务上加锁的,跳表自身并非线程安全,而单写的同时进行读或多读是没有问题的,至多未读取到最新数据而已。
查找过程是通过SkipList对应迭代器的Seek方法,仍然复用FindGreaterOrEqual,只不过不需记录前驱。
删除并没有提供直接的接口,删除实际也是通过插入实现,对已有数据删除是通过打kTypeDeletion标记并分配新的SequenceNumber,设置空value,构造新节点进行插入。
至此,leveldb最重要的内存存储MemTable实现到此结束。
refer:
1. http://www.cppblog.com/kongque/archive/2010/02/20/108093.html
2. http://blog.csdn.net/zhangxinrun/article/details/5940019