现有网上资料对于thrift生产环境下使用绝大多数为Java应用(protobuf仅提供序列化且很长时间没开放RPC框架,主体语言确定为C/C++时RPC选型thrift个人觉得是被动选择,当然grpc则是后话,生产环境下性能比较暂未看到相关分析),C++的相关资料极其缺乏,对于网络服务相关开发,nonblock io multiplexing+线程池对于单机应用来说更为常见,所以关于thrift系列开篇以TNonblockingServer模型的实现为例进行分析,其他模型及模块稍后会奉上。
本文以thrift-0.9.1+libevent-1.4.14b来分析TNonblockingServer的实现,公司开发机gcc 4.4.6不支持C++11,只得使用thirift的0.9.1版本,该thrift版本配套使用的libevent也只能使用1.4.X,对于最新的2.0.X有不少消息事件处理异常,具体问题并未来得及查明。
首先来介绍下thrift的源码组织结构和功能模块,如下图:

其中server, concurrency, processor, protocol, transport等是常用的几个重要模块,所处位置及功用如下:
- server: thrift提供的几个服务器模型,包括nonblocking server(多线程非阻塞IO), thread poll server(多线程阻塞IO)等,本文要分析的就是前者。
- concurrency:主要是thrift封装的对线程的创建、监控、管理等的支持。
- processor:对task的具体业务逻辑处理,与IDL方法定义自动生成的代码相关
- protocol:对IDL数据序列化/反序列化处理,与IDL对象定义自动生成的代码相关
- transport:通信协议传输层,涉及到TCP,HTTP等协议,PIPE方式通信,SSL协议等
其次,Client/Server的architecture图如下,此图来自网上用作对上述的直观补充^.^
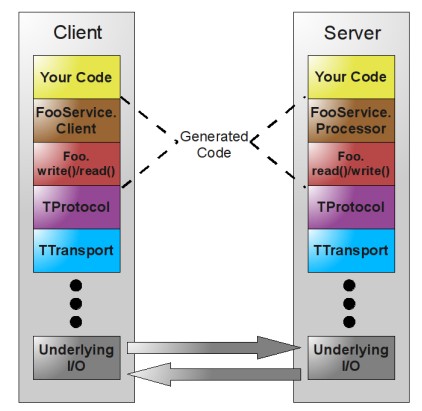
ok,让我们进入正题吧,先看下基本使用,再分析具体实现。TNonblockingServer的详细使用代码如下:
//工作线程实际使用的processor
shared_ptr recv_processor(new SendServProcessor(recv_handler));
//工作线程manager
shared_ptr<TProtocolFactory> recv_protocol_factory(new TBinaryProtocolFactory);
shared_ptr<ThreadManager> recv_thread_manager = ThreadManager::newSimpleThreadManager(recv_work_thread_num);
shared_ptr<PosixThreadFactory> recv_thread_factory = shared_ptr<PosixThreadFactory>(
new PosixThreadFactory(PosixThreadFactory::ROUND_ROBIN,
PosixThreadFactory::NORMAL,
8,
false));
recv_thread_manager->threadFactory(recv_thread_factory);
recv_thread_manager->start();
//TNonblockingServer的创建及启动
shared_ptr<TServer> recv_server = shared_ptr<TNonblockingServer>(
new TNonblockingServer(recv_processor,
recv_protocol_factory,
listen_port,
recv_thread_manager));
dynamic_pointer_cast<TNonblockingServer>(recv_server)->setNumIOThreads(io_thread_num);
dynamic_pointer_cast<TNonblockingServer>(recv_server)->serve();
recv_thread_manager->join();
关于thrift nonblocking server的调用流向,笔者作了一个简易的流程图(非学术规范)可供参考分析,省却大量文字描述,简单易懂。从上面代码的第23行serve方法进入server的serve loop,自顶向下的流程图如下: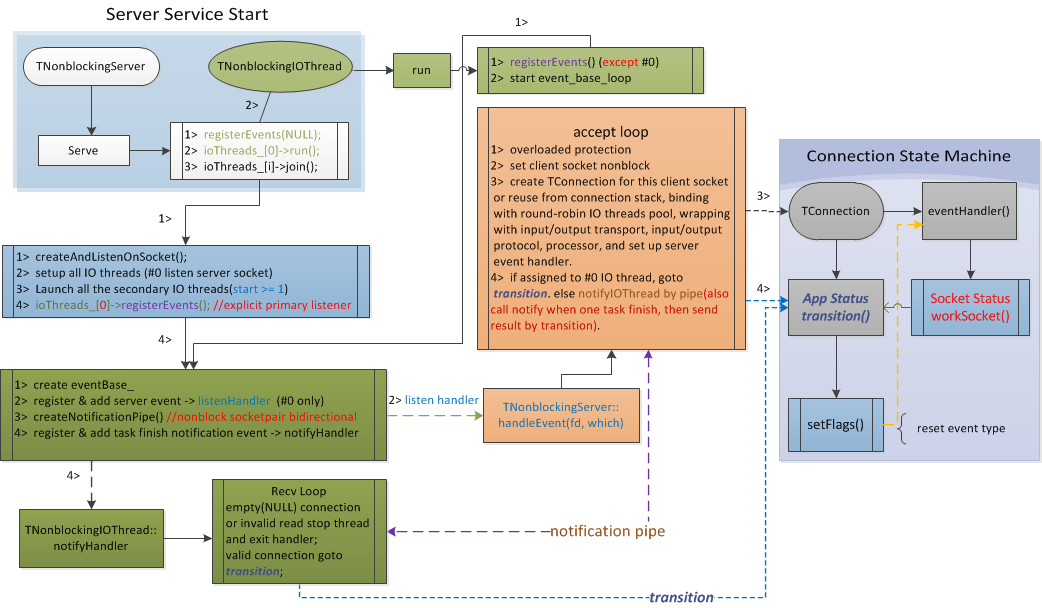
关于调用流程,有几点需要着重解释的:
1. 监听线程只有一个,即#0号IO线程。 当新连接被分配给0号线程,该连接会进入状态机转移注册相应IO事件,其它IO线程会通过pipe通知直接进入状态转移;
2. #0号IO线程与其它IO线程之间、IO线程与工作线程之间的通信是基于唯一的连接对象枢纽通过双向管道,即socketpair系统调用创建的unix local domain pipe进行通信,实现简洁高效;这种内部线程或进程间通信方式在其它网络库也很常见。
3. IO事件均依赖libevent库注册相关事件事件回调,这样使得框架更多关注于如编解码、任务封装、具体的业务执行等,IO、work分工协作,增强通用性;
4. 对于连接状态机不再作具体分析,具体可参考源码,比较简单清晰;像我们自己实现的网络框架也是类似,展示一个连接获取任务到执行完毕的不同状态间的transition。
5. 任务(Task)封装是包含连接(TConnection)在内,而连接的创建包含了工作线程的执行体(TProcessor)且创建时机是在监听到新连接分配IO线程时,连接(长)的生命周期远长于Task,而IO线程在数据接收完成后进行Task封装,工作线程仅仅去执行Task对应的TProcessor而不关注其它额外如初始化工作等。
6. 所有工作线程是共享一个有工作线程池所管理的任务队列;个人认为这里可以修改为每个工作线程可独占一个任务队列,有主线程对task做负载分配(如轮询),可明显减少多个工作线程争用同一task队列的全局锁开销。
7. 对于工作线程较重客户端又急需回复确认时,需要做相应的任务分解和具体的业务执行优化,或者增加相关缓冲提高业务处理,或者业务上异步处理,否则会造成QPS下降。
笔者会继续对thrift的服务器模型作源码剖析,上面的简易流程图请右键大图查阅,简单清晰,可知一反三。先到这吧,作图挺花费时间的~
refer:
1. https://thrift.apache.org/
2. http://dongxicheng.org/search-engine/thrift-framework-intro/