KMP 取自Knuth-Morris-Pratt 三人,一种字符串查找算法。
对于加快字符串的匹配查找,一般会对字符串做预处理然后再进行匹配查找,一种是对源串做预处理,另一种是对目标串(模式串)做预处理;KMP算法则是后者。
拿模式串在源串中进行比较匹配,当源串指针与模式串指针对应值不匹配时,源串指针无需向前回溯重头开始,仅通过移动模式串指针从而完成匹配,这是KMP的算法逻辑,那模式串指针该如何移动呢?模式串指针与源串已匹配到某一位置而无法继续,根据已有的匹配情况,需要跳转到下一位置继续匹配,这个跳转实质就是该模式串的DFA(确定有限状态自动机),因此对模式串的预处理就是构造DFA,实现状态转移,构造DFA的过程实质是寻找该模式串的自匹配程度,引申下就是计算该模式串的特征向量,在具体的算法分析中实际就是next数组,该数组代表了模式串的自匹配程度,即对应的特征向量。
如何用通俗的语言解释和简单的方法计算该特征向量呢?也就是该如何求next数组?
大部头算法导论给出了next数组定义如下: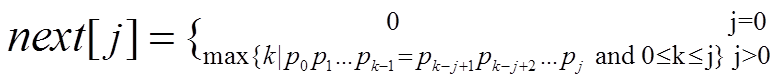
用通俗的语言解释上述定义就是:
模式串当前子串对应的next值实质是该子串对应的前缀数组与后缀数组的最长公共串的长度,也即待比较的前缀下一字符在模式串数组中的对应索引位置值,也就是模式串当前待匹配位置应该与哪个位置继续比较,这个“哪个位置”就是已匹配的next值。
举例来看pattern: abababca,j=4时,pattern当前子串为ababa,则前缀数组和后缀数组分别如下(均不包含自身):
 由前缀数组和后缀数组可知,最长公共串为aba,长度为3,则next[4]为3。据此可计算整个pattern串的next数组对应如下:
由前缀数组和后缀数组可知,最长公共串为aba,长度为3,则next[4]为3。据此可计算整个pattern串的next数组对应如下:

那该如何实现呢?计算pattern串的next数组的过程也就是计算模式串自匹配的过程,每一步计算要基于已有的匹配得出,仍然以开始计算j=4时为例,基于已有匹配j=3时next[3]=2,说明存在j=3前缀长度为2与j=3后缀长度为2相等,若前缀下一字符与后缀后一字符相等,则next[3]+1的值即为next[4]的值。需要注意的是,next值为长度值从前缀方向看实际也是下一字符的数组索引位置值,已有匹配的后缀后一字符即当前正在计算的待匹配字符,所以若相等必定长度加1;若不等,则更新已有匹配为前缀方向不匹配位置的前一位置(实质在向前回溯),拿该位置的next值继续比较,若仍然不匹配相等,则可能很快就到了模式串的起始位置。
上面的算法讲解还是比较清晰易懂的,如果搜索网文会发现大量的云里雾里绕来绕去,关键部分一笔掠过。现在我们拿出next数组的实现代码吧~参考如下,思想和上述讲解是完全一致的~
void GetNext(string pattern, int *next)
{
i = 0; j = -1;
while (i < pattern.length()) {
while (j > 0 && pattern[i] != pattern[j]) {
j = next[j - 1];
}
if (j == -1 || pattern[i] == pattern[j]) {
++ j;
}
next[i] = j;
++ i;
}
}
refer:
1. https://en.wikipedia.org/wiki/Knuth–Morris–Pratt_algorithm